03
Mar
If you’re looking for why spark is faster than mapreduce images information linked to the why spark is faster than mapreduce keyword, you have visit the ideal blog. Our website always gives you hints for viewing the highest quality video and picture content, please kindly search and find more enlightening video articles and graphics that match your interests.
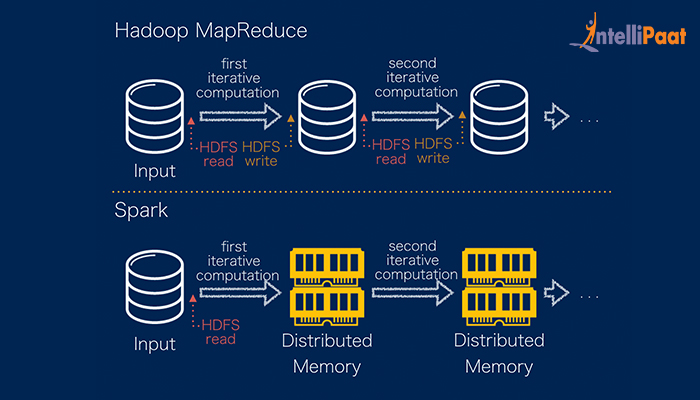
Why Spark Is Faster Than Mapreduce. Spark uses lazy evaluation with the help of DAG Directed Acyclic Graph of consecutive transformations. This reduces data shuffling and the execution is optimized. Apache Spark utilizes RAM and isnt tied to Hadoops two-stage paradigm. In some cases Spark can be up to 100 times faster than MapReduce.

Processing at high speeds. It runs 100 times faster in-memory and 10 times faster on disk than Hadoop MapReduce. This makes it faster than MapReduce. Apache Spark works well for smaller data sets that can all fit into a servers RAM. It is a framework that is open-source which is used for writing data into the Hadoop Distributed File System. Apache Spark is now more popular that Hadoop MapReduce.
The reason is that Apache Spark processes data in-memory RAM while Hadoop MapReduce has to persist data back to the disk after every Map or Reduce action. Spark caches the in-memory data for further iterations so its very fast as compared to Map Reduce. Why is Apache Spark faster than MapReduce. It just needs making an RPC and adding the Runnable to the thread pool. First of all Spark is not faster than Hadoop. The process of Spark execution can be up to 100 times faster due to its inherent ability to exploit the memory rather than using the disk storage.
Previous post
Wilcox model financial distress